Fema Guidence on Uploading Data via File Explore Fema Guidance on Uploading Data via File Explorer
This browser is no longer supported.
Upgrade to Microsoft Border to take advantage of the latest features, security updates, and technical support.
Disaster recovery and storage account failover
Microsoft strives to ensure that Azure services are always available. However, unplanned service outages may occur. If your awarding requires resiliency, Microsoft recommends using geo-redundant storage, and so that your data is copied to a second region. Additionally, customers should accept a disaster recovery plan in place for handling a regional service outage. An of import part of a disaster recovery plan is preparing to fail over to the secondary endpoint in the event that the principal endpoint becomes unavailable.
Azure Storage supports account failover for geo-redundant storage accounts. With account failover, you can initiate the failover process for your storage account if the primary endpoint becomes unavailable. The failover updates the secondary endpoint to get the chief endpoint for your storage account. Once the failover is complete, clients can brainstorm writing to the new main endpoint.
Account failover is bachelor for general-purpose v1, general-purpose v2, and Blob storage account types with Azure Resource Director deployments. Business relationship failover is not supported for storage accounts with a hierarchical namespace enabled.
This commodity describes the concepts and process involved with an account failover and discusses how to prepare your storage account for recovery with the least amount of customer impact. To acquire how to initiate an account failover in the Azure portal or PowerShell, see Initiate an business relationship failover.
Cull the right redundancy selection
Azure Storage maintains multiple copies of your storage account to ensure durability and high availability. Which back-up pick you cull for your account depends on the degree of resiliency you need. For protection against regional outages, configure your account for geo-redundant storage, with or without the option of read access from the secondary region:
Geo-redundant storage (GRS) or geo-zone-redundant storage (GZRS) copies your data asynchronously in ii geographic regions that are at least hundreds of miles apart. If the principal region suffers an outage, then the secondary region serves as a redundant source for your data. You tin initiate a failover to transform the secondary endpoint into the chief endpoint.
Read-access geo-redundant storage (RA-GRS) or read-access geo-zone-redundant storage (RA-GZRS) provides geo-redundant storage with the additional benefit of read admission to the secondary endpoint. If an outage occurs in the primary endpoint, applications configured for read access to the secondary and designed for loftier availability can go on to read from the secondary endpoint. Microsoft recommends RA-GZRS for maximum availability and immovability for your applications.
For more data most back-up in Azure Storage, see Azure Storage redundancy.
Warning
Geo-redundant storage carries a gamble of data loss. Data is copied to the secondary region asynchronously, meaning there is a filibuster between when data written to the master region is written to the secondary region. In the result of an outage, write operations to the principal endpoint that have not yet been copied to the secondary endpoint will be lost.
Blueprint for loftier availability
It's important to blueprint your awarding for loftier availability from the commencement. Refer to these Azure resources for guidance in designing your application and planning for disaster recovery:
- Designing resilient applications for Azure: An overview of the key concepts for architecting highly bachelor applications in Azure.
- Resiliency checklist: A checklist for verifying that your application implements the best design practices for high availability.
- Apply geo-redundancy to design highly available applications: Design guidance for building applications to take advantage of geo-redundant storage.
- Tutorial: Build a highly bachelor application with Blob storage: A tutorial that shows how to build a highly available application that automatically switches betwixt endpoints as failures and recoveries are simulated.
Additionally, go along in heed these best practices for maintaining high availability for your Azure Storage data:
- Disks: Employ Azure Backup to support the VM disks used by your Azure virtual machines. Also consider using Azure Site Recovery to protect your VMs in the issue of a regional disaster.
- Block blobs: Turn on soft delete to protect confronting object-level deletions and overwrites, or re-create cake blobs to another storage business relationship in a different region using AzCopy, Azure PowerShell, or the Azure Data Motion library.
- Files: Employ Azure Backup to support your file shares. Also enable soft delete to protect confronting accidental file share deletions. For geo-redundancy when GRS is not available, utilise AzCopy or Azure PowerShell to copy your files to another storage account in a different region.
- Tables: utilize AzCopy to export table data to some other storage account in a different region.
Track outages
Customers may subscribe to the Azure Service Health Dashboard to rails the wellness and status of Azure Storage and other Azure services.
Microsoft as well recommends that you design your application to prepare for the possibility of write failures. Your awarding should betrayal write failures in a way that alerts you to the possibility of an outage in the chief region.
Understand the account failover process
Client-managed account failover enables you to neglect your entire storage account over to the secondary region if the main becomes unavailable for any reason. When yous strength a failover to the secondary region, clients tin begin writing information to the secondary endpoint later on the failover is complete. The failover typically takes about an 60 minutes.
Note
Client-managed business relationship failover is non yet supported in accounts that take a hierarchical namespace (Azure Data Lake Storage Gen2). To learn more, see Blob storage features available in Azure Information Lake Storage Gen2.
In the effect of a disaster that affects the primary region, Microsoft will manage the failover for accounts with a hierarchical namespace. For more information, see Microsoft-managed failover.
How an account failover works
Nether normal circumstances, a client writes data to an Azure Storage business relationship in the main region, and that data is copied asynchronously to the secondary region. The post-obit prototype shows the scenario when the chief region is available:
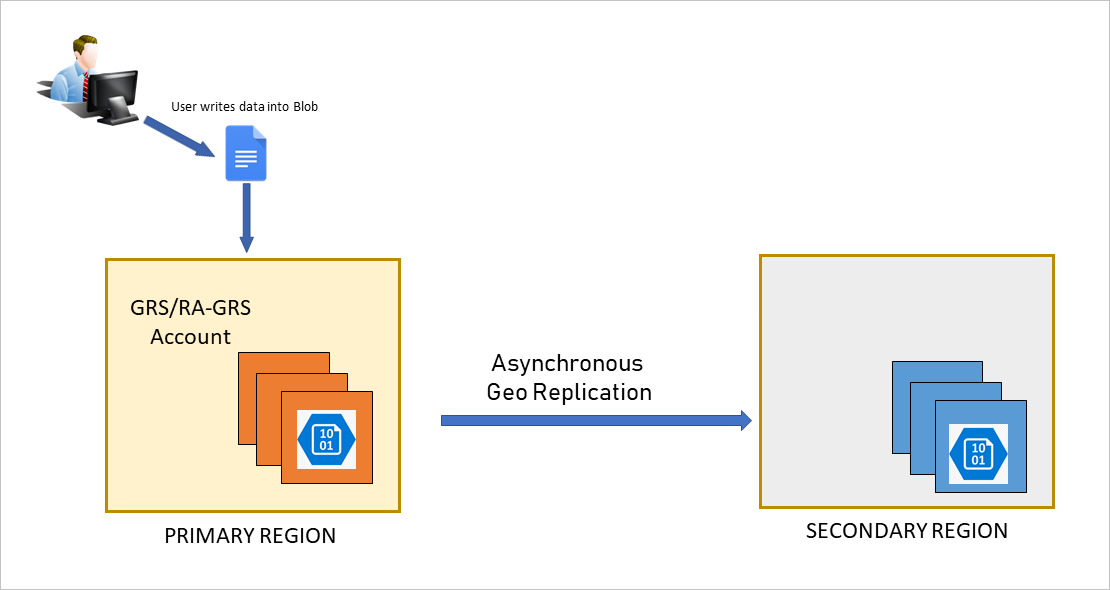
If the chief endpoint becomes unavailable for any reason, the client is no longer able to write to the storage account. The following epitome shows the scenario where the primary has become unavailable, but no recovery has happened yet:

The client initiates the account failover to the secondary endpoint. The failover process updates the DNS entry provided by Azure Storage then that the secondary endpoint becomes the new primary endpoint for your storage business relationship, as shown in the following epitome:
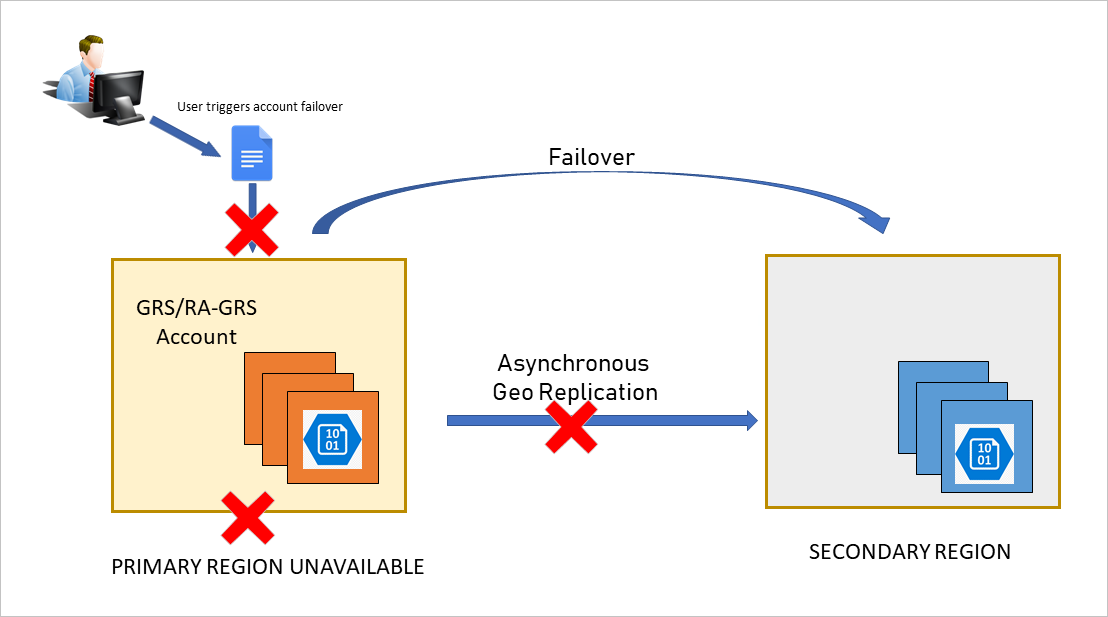
Write access is restored for geo-redundant accounts once the DNS entry has been updated and requests are being directed to the new primary endpoint. Existing storage service endpoints for blobs, tables, queues, and files remain the aforementioned after the failover.
Important
After the failover is complete, the storage account is configured to be locally redundant in the new primary endpoint. To resume replication to the new secondary, configure the account for geo-redundancy again.
Go along in heed that converting a locally redundant storage business relationship to employ geo-redundancy incurs both cost and time. For more data, run into Important implications of business relationship failover.
Anticipate information loss
Caution
An account failover normally involves some data loss. It's of import to empathise the implications of initiating an account failover.
Because data is written asynchronously from the chief region to the secondary region, in that location is always a delay earlier a write to the primary region is copied to the secondary region. If the primary region becomes unavailable, the most recent writes may not yet take been copied to the secondary region.
When you force a failover, all information in the primary region is lost every bit the secondary region becomes the new main region. The new principal region is configured to be locally redundant after the failover.
All data already copied to the secondary is maintained when the failover happens. However, any data written to the primary that has not also been copied to the secondary is lost permanently.
The Last Sync Fourth dimension property indicates the most recent time that data from the primary region is guaranteed to accept been written to the secondary region. All information written prior to the last sync time is available on the secondary, while data written afterwards the last sync fourth dimension may not have been written to the secondary and may be lost. Use this property in the event of an outage to estimate the amount of information loss y'all may incur by initiating an account failover.
As a all-time practice, design your application so that you lot can use the terminal sync fourth dimension to evaluate expected information loss. For example, if y'all are logging all write operations, and so you can compare the time of your final write operations to the concluding sync time to determine which writes have not been synced to the secondary.
For more than information about checking the Last Sync Fourth dimension property, come across Check the Final Sync Time property for a storage account.
Utilise caution when failing dorsum to the original main
After you fail over from the primary to the secondary region, your storage account is configured to be locally redundant in the new primary region. Y'all can and so configure the account in the new primary region for geo-redundancy. When the business relationship is configured for geo-redundancy later on a failover, the new primary region immediately begins copying data to the new secondary region, which was the main before the original failover. However, information technology may take some time earlier existing data in the new primary is fully copied to the new secondary.
Subsequently the storage account is reconfigured for geo-redundancy, it's possible to initiate a failback from the new primary to the new secondary. In this case, the original primary region prior to the failover becomes the primary region once again, and is configured to be either locally redundant or zone-redundant, depending on whether the original primary configuration was GRS/RA-GRS or GZRS/RA-GZRS. All data in the mail service-failover main region (the original secondary) is lost during the failback. If near of the data in the storage account has not been copied to the new secondary before you fail back, you could endure a major data loss.
To avoid a major data loss, check the value of the Terminal Sync Time holding before failing back. Compare the terminal sync time to the final times that information was written to the new principal to evaluate expected data loss.
Subsequently a failback operation, you tin configure the new chief region to be geo-redundant again. If the original primary was configured for LRS, you can configure it to exist GRS or RA-GRS. If the original primary was configured for ZRS, yous tin can configure information technology to be GZRS or RA-GZRS. For additional options, see Change how a storage account is replicated.
Initiate an business relationship failover
You can initiate an account failover from the Azure portal, PowerShell, Azure CLI, or the Azure Storage resources provider API. For more than information on how to initiate a failover, see Initiate an business relationship failover.
Boosted considerations
Review the boosted considerations described in this section to sympathise how your applications and services may exist affected when you force a failover.
Storage account containing archived blobs
Storage accounts containing archived blobs support account failover. Later on failover is complete, all archived blobs need to be rehydrated to an online tier before the account can exist configured for geo-redundancy.
Storage resource provider
Microsoft provides two REST APIs for working with Azure Storage resources. These APIs class the basis of all actions you tin perform against Azure Storage. The Azure Storage Residual API enables you to piece of work with information in your storage account, including blob, queue, file, and table data. The Azure Storage resource provider REST API enables yous to manage the storage account and related resources.
After a failover is complete, clients tin can over again read and write Azure Storage data in the new primary region. However, the Azure Storage resource provider does not fail over, so resource management operations must still accept place in the chief region. If the principal region is unavailable, yous will non be able to perform management operations on the storage account.
Because the Azure Storage resource provider does not fail over, the Location property will return the original primary location after the failover is complete.
Azure virtual machines
Azure virtual machines (VMs) do not fail over every bit role of an account failover. If the primary region becomes unavailable, and you fail over to the secondary region, then you will need to recreate any VMs after the failover. Also, there is a potential data loss associated with the business relationship failover. Microsoft recommends the following high availability and disaster recovery guidance specific to virtual machines in Azure.
Azure unmanaged disks
As a best practice, Microsoft recommends converting unmanaged disks to managed disks. However, if y'all need to fail over an account that contains unmanaged disks attached to Azure VMs, yous will need to shut down the VM before initiating the failover.
Unmanaged disks are stored every bit page blobs in Azure Storage. When a VM is running in Azure, any unmanaged disks fastened to the VM are leased. An business relationship failover cannot proceed when there is a lease on a blob. To perform the failover, follow these steps:
- Earlier you brainstorm, note the names of any unmanaged disks, their logical unit of measurement numbers (LUN), and the VM to which they are attached. Doing and so will make information technology easier to reattach the disks after the failover.
- Shut downwardly the VM.
- Delete the VM, just retain the VHD files for the unmanaged disks. Note the time at which yous deleted the VM.
- Wait until the Final Sync Fourth dimension has updated, and is later than the time at which you deleted the VM. This stride is important, because if the secondary endpoint has not been fully updated with the VHD files when the failover occurs, then the VM may non role properly in the new chief region.
- Initiate the account failover.
- Expect until the business relationship failover is complete and the secondary region has become the new primary region.
- Create a VM in the new primary region and reattach the VHDs.
- Start the new VM.
Go along in mind that any data stored in a temporary deejay is lost when the VM is shut down.
Unsupported features and services
The following features and services are not supported for account failover:
- Azure File Sync does not back up storage account failover. Storage accounts containing Azure file shares existence used as cloud endpoints in Azure File Sync should not be failed over. Doing so volition cause sync to stop working and may also cause unexpected data loss in the instance of newly tiered files.
- Storage accounts that have hierarchical namespace enabled (such every bit for Information Lake Storage Gen2) are not supported at this time.
- A storage account containing premium block blobs cannot be failed over. Storage accounts that support premium cake blobs do not currently support geo-back-up.
- A storage account containing whatever WORM immutability policy enabled containers cannot be failed over. Unlocked/locked time-based retentiveness or legal hold policies prevent failover in social club to maintain compliance.
Copying data as an alternative to failover
If your storage account is configured for read access to the secondary, then you tin design your application to read from the secondary endpoint. If you prefer not to fail over in the event of an outage in the main region, you tin use tools such as AzCopy, Azure PowerShell, or the Azure Information Movement library to copy data from your storage business relationship in the secondary region to another storage account in an unaffected region. You can and so point your applications to that storage account for both read and write availability.
Circumspection
An account failover should not be used as part of your data migration strategy.
Microsoft-managed failover
In extreme circumstances where a region is lost due to a significant disaster, Microsoft may initiate a regional failover. In this case, no activity on your part is required. Until the Microsoft-managed failover has completed, you won't have write access to your storage account. Your applications tin can read from the secondary region if your storage business relationship is configured for RA-GRS or RA-GZRS.
See also
- Apply geo-redundancy to design highly available applications
- Initiate an business relationship failover
- Check the Last Sync Time property for a storage account
- Tutorial: Build a highly bachelor application with Blob storage
Feedback
Submit and view feedback for
Source: https://docs.microsoft.com/en-us/azure/storage/common/storage-disaster-recovery-guidance
0 Response to "Fema Guidence on Uploading Data via File Explore Fema Guidance on Uploading Data via File Explorer"
Enregistrer un commentaire